CGRA4ML: Py+SV+C Framework for DNNs → FPGA/ASIC
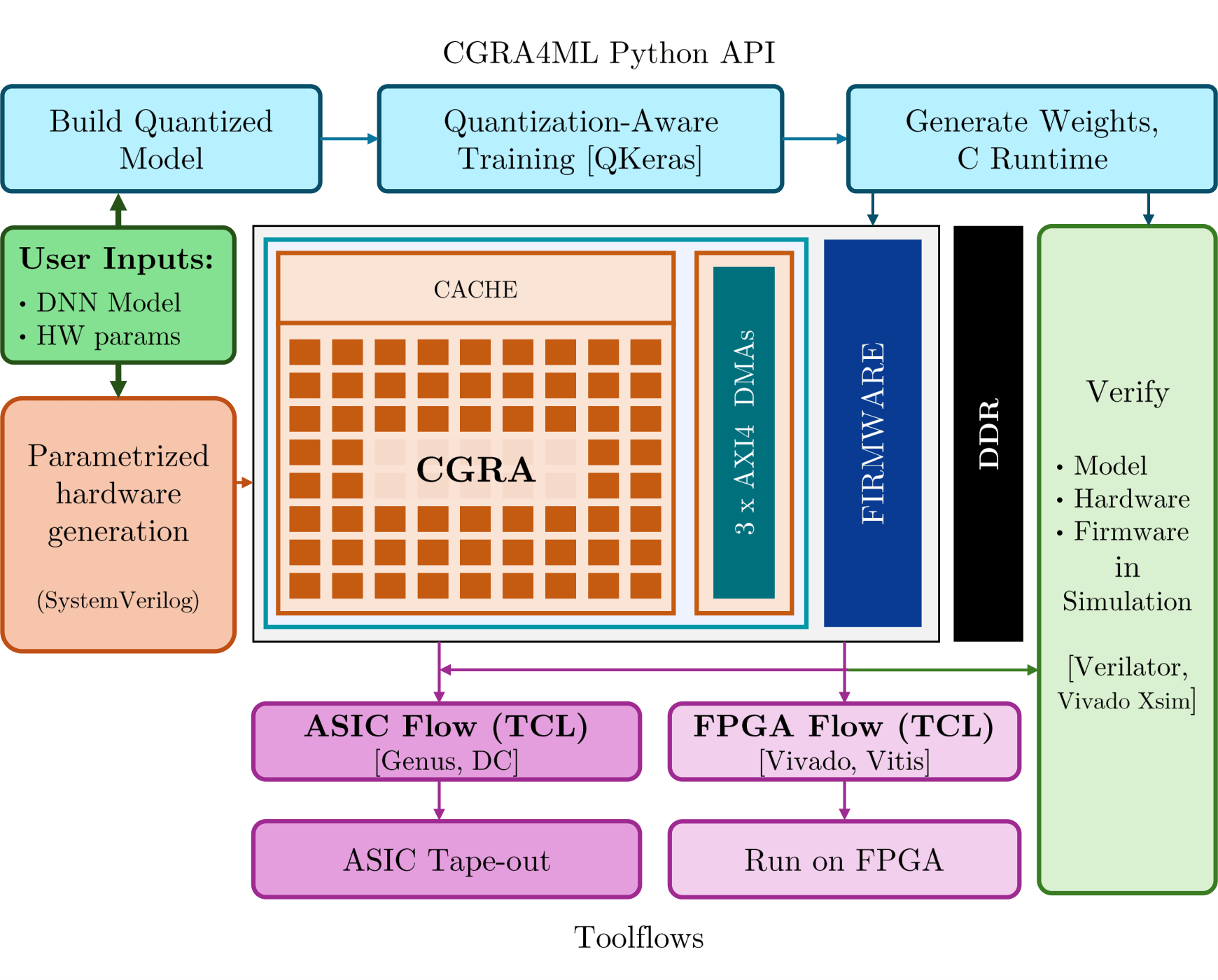
CGRA4ML is an open-source, modular hardware/software co-design framework built to implement deep neural networks (DNNs) for scientific edge computing applications.
Read our framework paper at ACM TRETS
While existing tools like hls4ml and FINN excel at small, low-latency models, they often struggle to scale to deeper networks. This is due to their layer-by-layer dataflow architecture, which consumes increasing hardware resources as model depth grows. CGRA4ML addresses this by employing a lightweight and highly parameterizable Coarse-Grained Reconfigurable Array (CGRA) that reuses processing elements (PEs) across layers. This approach enables the deployment of larger models, such as ResNet-50 and PointNet, on FPGAs and ASICs.
Features
- Python frontend built around Google’s
qkerasto build and train models. - Generates a custom, parameterized AXI-Stream Deep Neural Network (DNN) CGRA engine in vendor-agnostic SystemVerilog RTL.
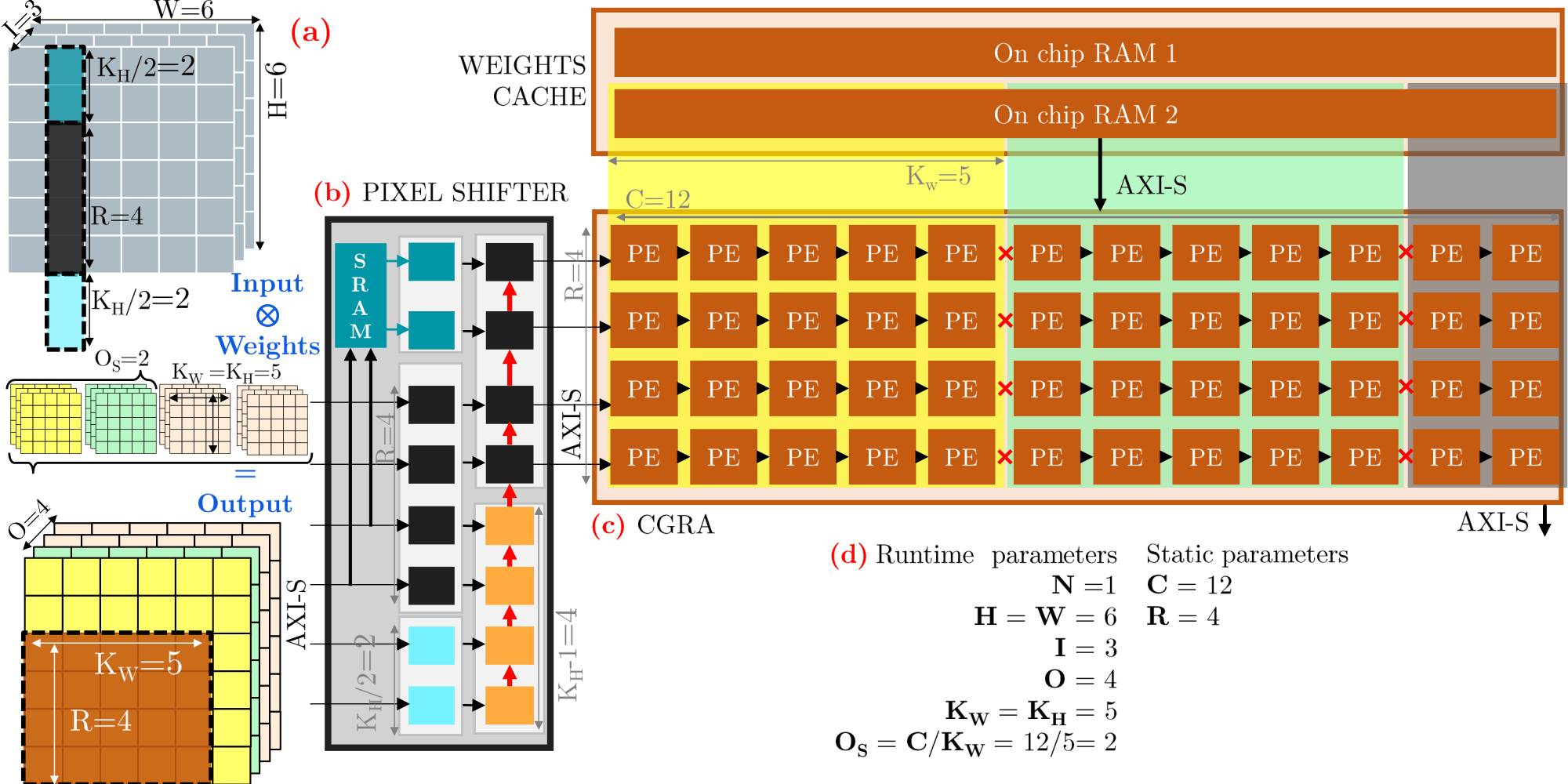
- Dynamic Column Regrouping: Columns in the 2D PE array can regroup at runtime to process varying convolution kernel widths and output channels.
- Memory Efficiency: Weight cache with ping-pong buffers for full throughput and a pixel shifter that exploits vertical data locality to reduce required input bandwidth.
- Unified Dataflow Architecture maximizing data reuse via weight caches (ping-pong buffers) and pixel-shifters.
- “Bundle” computation architecture for hardware/software partitioning. Dense, convolutional operations stay on the CGRA while skip connections or complex pixel operations are CPU-handled.
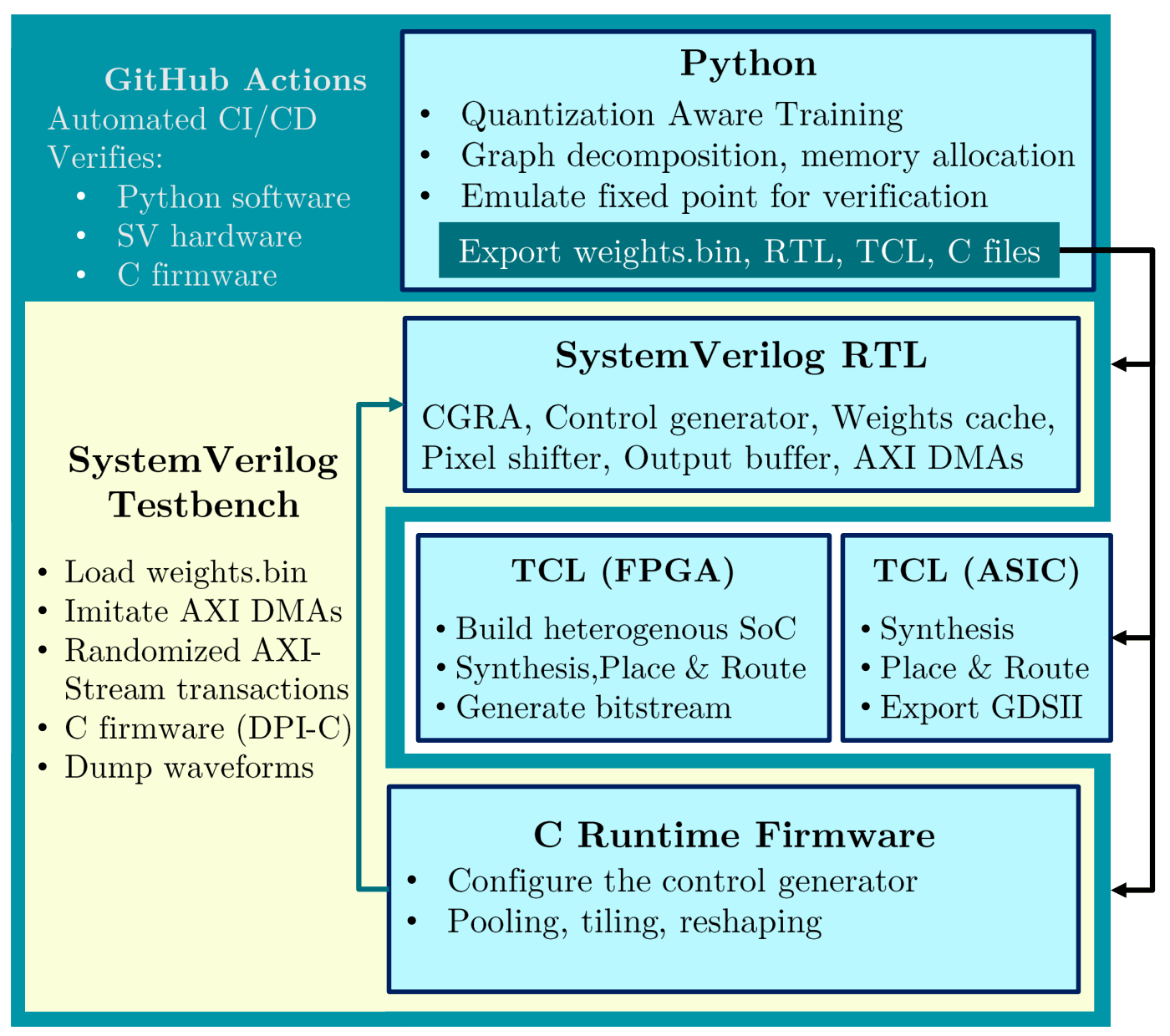
- Verification via FireBridge & AXI-Stream VIP: Comprehensive system verification using SystemVerilog DPI-C wrappers and a testbench that runs the same C-firmware to uncover real memory congestion bugs with randomized AXI
ready/validsignals. - Supports full System-on-Chip integration (e.g., ZYNQ, Ibex RISC-V SoC, ARM NanoSoC).
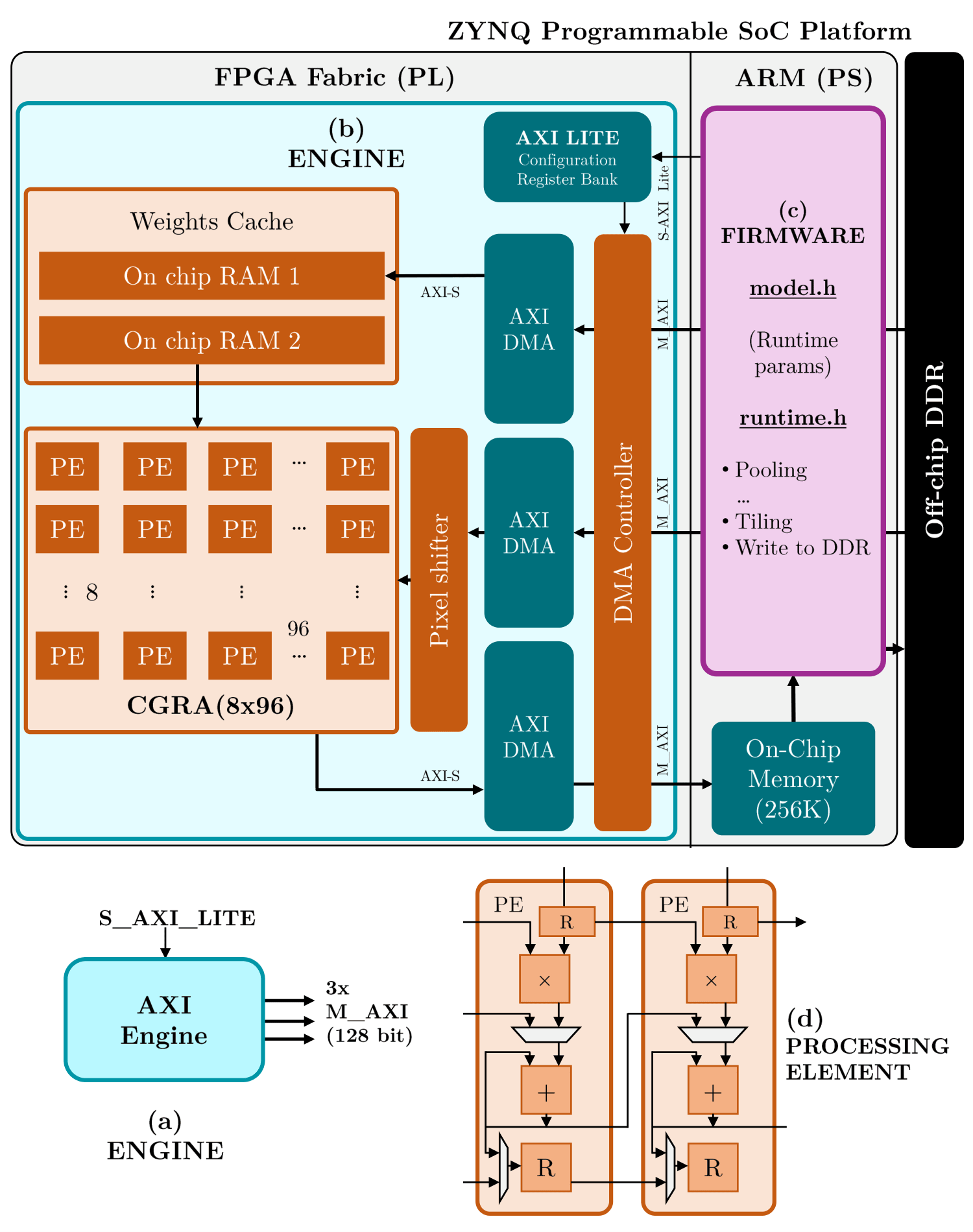
Unified Dataflow
Validation and Results
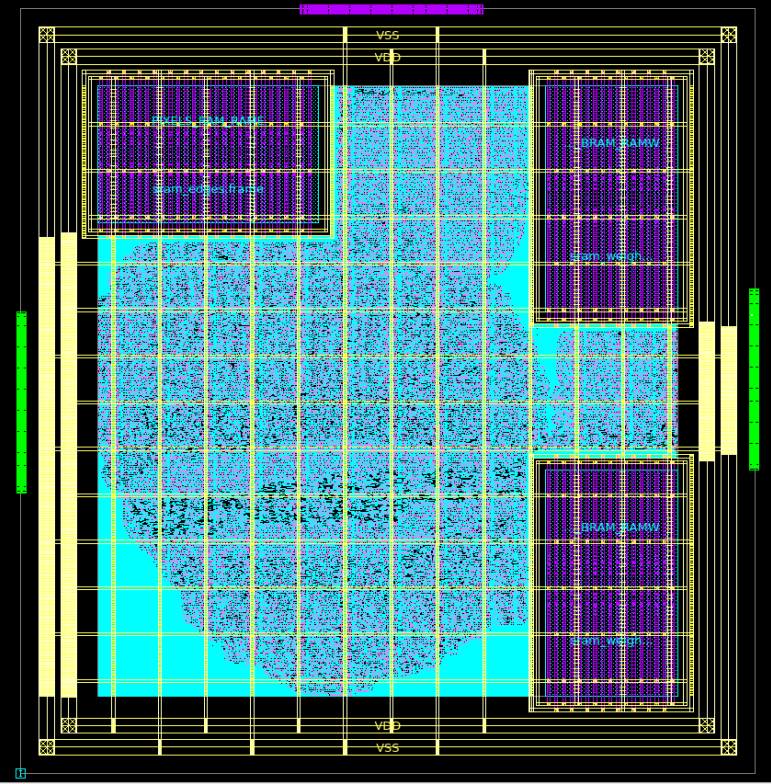
The framework has been experimentally validated on AMD-Xilinx FPGAs and Cadence ASIC flows. Iso-resource microbenchmarking on a Pynq-Z2 at 150 MHz shows that while hls4ml excels at small workloads, fitting larger workloads requires an exponentially increasing reuse factor. In contrast, a 16x16 CGRA4ML array maintains stable latency and higher throughput when extreme resource constraints are required.
Deployment is streamlined via automated TCL scripts for synthesis, floorplanning, and SoC integration—including integration with the popular Ibex RISC-V SoC. By filling the gap between small-model dataflow tools and traditional 8-bit AI accelerators, CGRA4ML enables the scientific community to move sophisticated processing to extreme edge hardware.
Check out the repo here: GitHub - cgra4ml